Creating the most capable text-to-image model with improved performance.
About
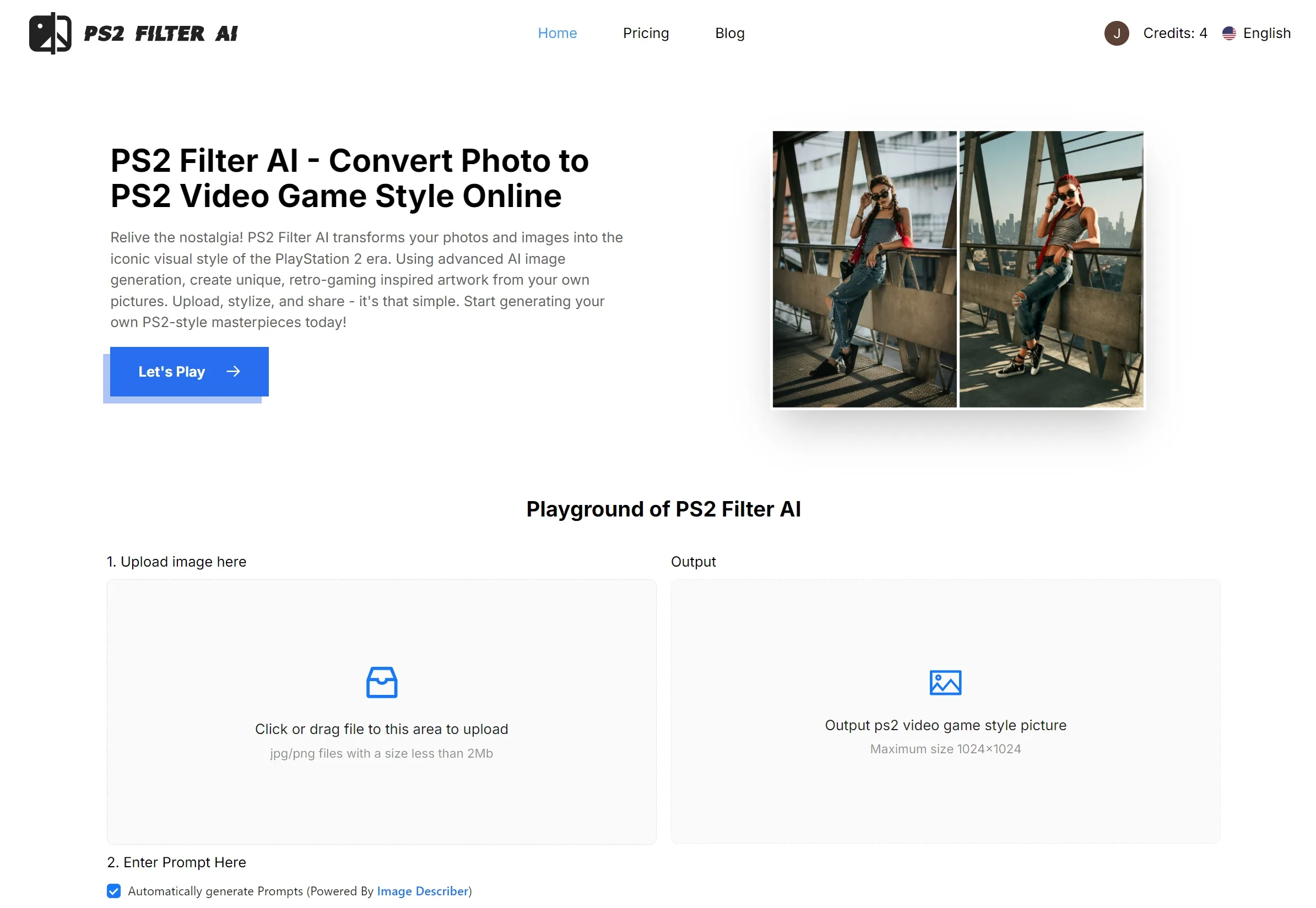
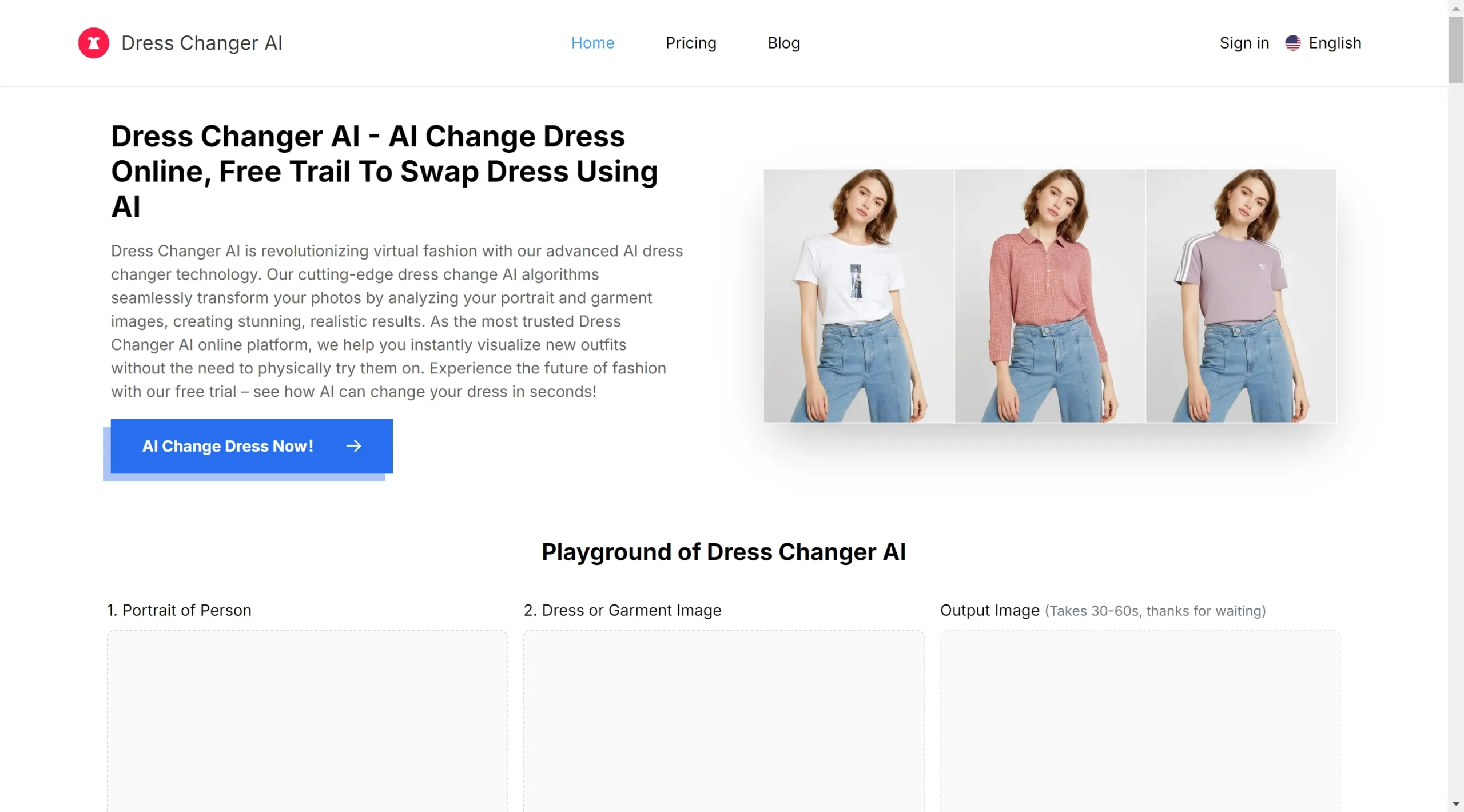
Stable Diffusion 3 is a state-of-the-art text-to-image model developed by Stability AI. Its purpose is to translate textual prompts into visually accurate and high-quality images. It marks a significant leap in the company’s AI capabilities, demonstrating substantial enhancements in its handling of multi-subject prompts, image quality, and spelling abilities. One of the unique features of Stable Diffusion 3 is its scalability, catering to diverse creative needs through its suite of models. It incorporates a diffusion transformer architecture and flow matching for improved performance.Despite the technological advancement, the model is not yet broadly available, but a waitlist has been opened for early users to preview the tool prior to official release. This preview phase plays an essential role in gathering user insights which are instrumental in refining and ensuring the system’s safety and performance before the public launch. Stability AI follows prudent AI practices with safety being a key priority throughout the model’s training, testing, evaluation and deployment phases. To achieve this, the company employs numerous safeguards during the preparation of its early preview, ensuring the prevention against misuse of the model by hostile actors. The ultimate goal of Stable Diffusion 3 is to offer adaptable solutions that empower individuals, developers, and enterprises to express their creativity, without compromising on openness, safety, and universal accessibility. Users interested in other text-to-image models for commercial use in the meantime can explore Stability AI’s Membership or Developer Platform.